
Cloud-native solutions that use microservices and functions disaggregated from hardware are increasingly adopted. The need to evolve towards such an architecture is to realise the potential of new technologies (5G, SDN, AI/ML, Data, Cloud, slicing, etc.), to manage the complexity of the Services of the future, to provide a personalised and optimised customer experience in real time, and to build the future of the network as a service.
In that sense, in the area of network operations and services, it is important to evolve also in the sense of anticipating problems and solving them automatically. Increasing agility in all processes and autonomously managing the entire operational process is a ‘sine qua non’ condition for survival in the near future.
In this context, evolving from Network Monitoring to Observability of networks and services is the way to face this new challenge.
What is the difference between observability and monitoring?
Observability does not replace monitoring, but takes advantage of what monitoring already does, incorporates other data sources and correlates them in a way that these inputs explain certain behaviours and states of the network.
This whole environment that makes up the concept of Observability is supported by various capabilities and tools that bring together a large number of very diverse data sources, including those from outside the network. Such an environment must have the ability to select and maintain optimal control over a complex, changing and dynamic system.
Observability environments discover, gather and aggregate information by integrating with existing monitoring and other sources, and provide aggregation of these components. Fundamentally, Observability focuses on four main types of data sources:
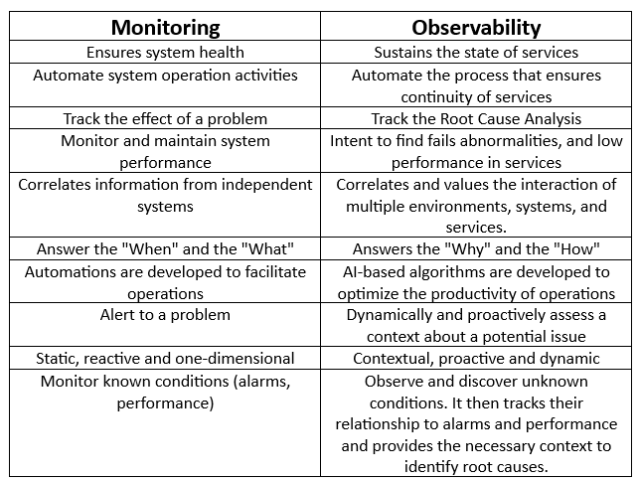
A more complete way to understand the main characteristics of Monitoring and Observability is to compare key aspects that differentiate them. The comparison table highlights the main characteristics that allow understanding the main differences between the two ways of managing networks, systems and services.
Monitoring Observability
- Ensures system status Supports the status of services
- Automates system operation activities Automates the process that ensures service continuity
- Tracks the effect of a problem Tracks the Root-Cause of an abnormality
- Monitors and preserves the performance of systems Attempts to find faults, abnormalities and underperformance in services
- Correlates information from independent systems Correlates and assesses the interaction of multiple environments, systems and services.
- Answers the ‘When’ and the ‘What’ Answers the ‘Why’ and the ‘How’.
- Automations are developed to facilitate operations AI-based algorithms are developed to optimise the productivity of operations
- Alerts on a problem Evaluates a context dynamically and proactively on a potential problem
- Static, reactive and one-dimensional Contextual, pro-active and dynamic
- Monitors known conditions (alarms, performance) Observes and discovers unknown conditions. Then tracks their relationship with alarms and performance and provides the necessary context to identify root causes.
What needs to be done to evolve towards Observability?
Evolving from Monitoring to Observability involves adopting new tools, new developments and mainly practices that provide more complete visibility. It implies a new way of executing the process.
To achieve this evolution, Observability platforms must be integrated with existingFault Management andPerformance Management tools, in addition to other existing platforms in the application and infrastructure components. In turn, the compilation of performance and fault data has to be continuous and real-time. Once the data is collected, Observability platforms fully exploit the data and information and correlate it in real time, allowing teams to understand the what, where, how and why of any event or abnormality that may indicate or cause a potential abnormality.
Observability environments also includeAIOps (AI for Operations – discussed in more detail below) capabilities that add intelligence in debugging and help separate irrelevant information and noise from the actual problem to be solved, i.e. filter out data that is not related to the root cause and exclude it from the problem solution. In addition to this, it is possible to have automation in the processes that will allow the automated repair of the infrastructure and applications, thus completing the cycle of identification, diagnosis and solution of the incident. It should be emphasised that it is very important to have a reliable, context-rich and fully correlated log, as this provides a solid basis for automated analysis and resolution of problems.
Finally, the transition to Observability requires a change in organisational culture, where teams must be trained and have the culture to use the tools and approach that Observability offers.
AIOps, a path to consistent Observability
AIOps (Artificial Intelligence for Network and Systems Operations) is the term used to refer to the use of Artificial Intelligence (AI) technologies to automate, optimise and bring intelligence to the management of services and workflows in operations.
AIOps emerges as the main tool to enable our operations areas to manage large amounts of data and hundreds of components from multiple environments and systems.
As a starting point, in AIOps contexts there is an impressive ability to filter relevant information and to focus on using the necessary data that makes sense for given analyses. Even AI-supported algorithms are able to uncover hidden problems that are not possible to know without the support of such a technique.
They are also designed to go beyond data collection. Their ability to correlate multiple sources of information in real time, diagnose problems quickly and provide a root cause for failures and underperformance situations is immense. In fact, this process of diagnosis and root-cause discovery is one of the greatest advantages that can be derived from AIOps to streamline solutions.
AIOps also goes further. These tools have the ability to automatically solve problems without human interference. Thus closing the full cycle of identification, assessment and solution. This approach, known as ‘closed-loop’, represents a very significant advance in the automation and operational intelligence of our operations.
Ultimately, the application of AIOps concepts not only improves data management, but also ensures greater efficiency and faster, more accurate problem resolution, definitively transforming the way we operate and observe networks and systems.
People, the greatest asset for the new Observability dynamic
This path to Observability leads us to think that operational processes are becoming more and more autonomous and intelligent and, because of this, there is less need for technicians to touch the network.
Here, we are also approaching the concept of zero-touch. In this new mindset of working more and more with the help of intelligence, the way of working is changing. In this sense, the main task of people’s capabilities in this new field of Observability is to:
Gain advantage in the new AI world to anticipate the problem and solve it before it happens.
- Service and customer orientation
- More proactive routines
- Move closer to Zero-touch (human-assisted system, not the other way around)
- Seek to continually refine operations algorithms
- DevOps and continuous learning culture






